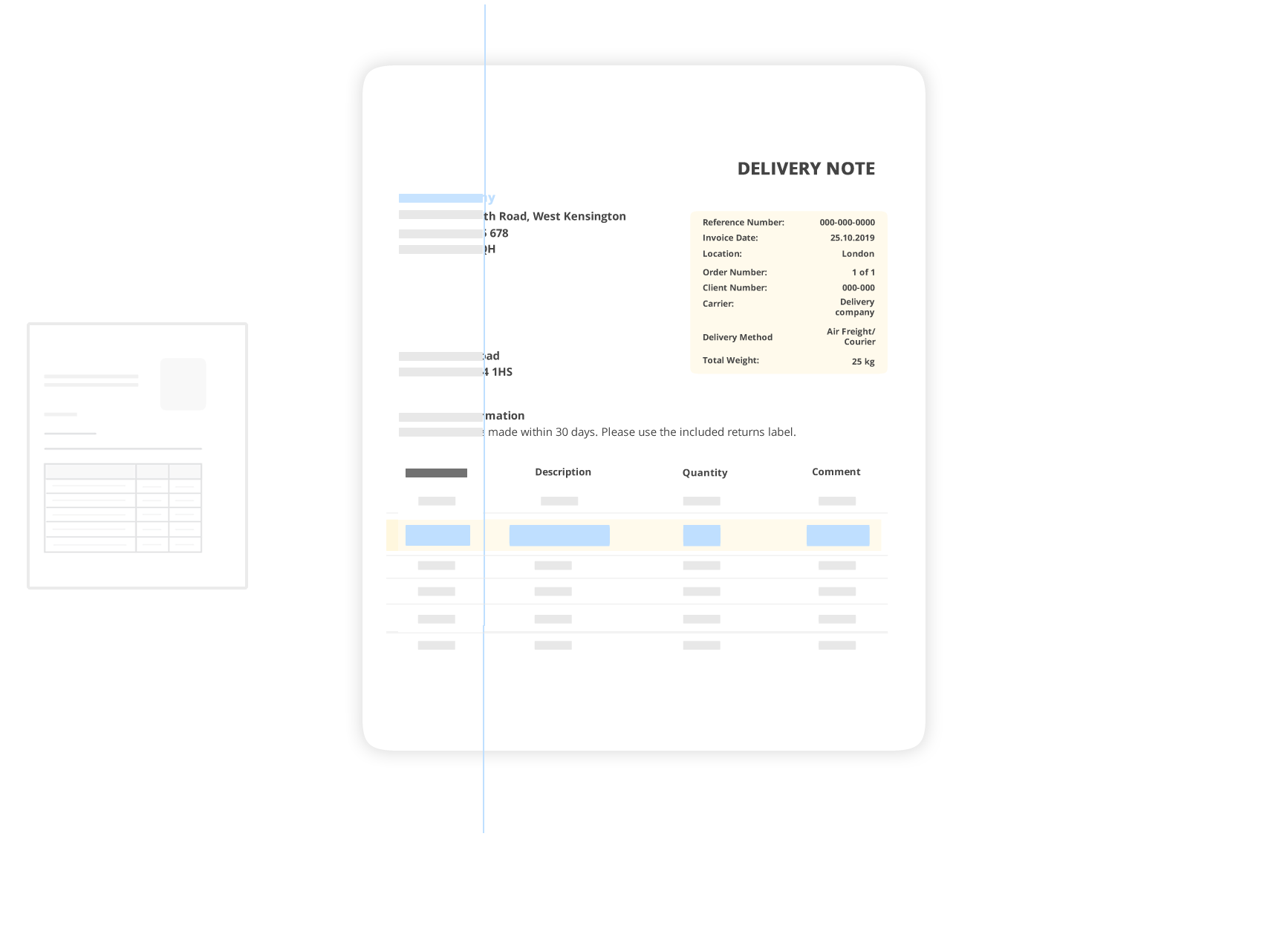
Практическая разница в ежедневной работе
Сценарий: Обработка счетов
Решающее различие:
Вам не нужно выбирать между OCR и ИИ. PaperOffice AI Smart Suite предлагает и то, и другое - интеллектуальный OCR+LLM для простых случаев и полные IDP-решения для сложных требований.
" style="border: 1px solid #EEEEEE; background-color: white;">
Классический OCR (Tesseract)
Компания ABC Ltd Образцовая улица 123 12345 Образцовый город
Номер счета 2024-0157 Дата 15/03/2024
Товар Канцелярские товары Нетто $1,049.00
НДС $198.83 Итого $1,247.83
Проблема: Сотрудник должен прочитать текст, извлечь релевантные данные и вручную категоризировать. Требуемое время: 8-12 минут на счет.
PaperOffice IDP Professional
{
"document_type": "invoice",
"vendor": {
"name": "Компания ABC Ltd",
"address": "Образцовая улица 123, 12345 Образцовый город"
},
"invoice_number": "2024-0157",
"invoice_date": "2024-03-15",
"line_items": [{
"description": "Канцелярские товары",
"net_amount": 1049.00
}],
"totals": {
"net": 1049.00,
"tax": 198.83,
"gross": 1247.83,
"currency": "USD"
},
"confidence": 100
}
Результат: Прямая интеграция в ERP-систему, возможна визуальная проверка. Время IDP: менее 10 секунд на счет.
Правда о затратах: Что вы действительно платите
Tesseract (Open Source)
- Программное обеспечение: $0
- Постобработка: 8-12 мин/документ
- На 1000 счетов/месяц:
Рабочее время: 167ч × $25/ч = $4,175/месяц
Скрытые годовые затраты: $50,100
ABBYY FlexiCapture
- Цена: 5-15 центов/страница
- Настройка + Лицензия: $15,000-50,000
- На 10,000 страниц/месяц:
$500-1,500/месяц + базовые затраты
Годовые затраты: $35,000-80,000
Где системы на основе LLM показывают свои преимущества
Тест точности: Конкретные цифры
Точность распознавания на реальных бизнес-документах:
- Tesseract 4.0: 89-94% (чистые сканы), 65-80% (сложные документы)
- ABBYY FineReader: 96-98% (с обучением), 85-92% (из коробки)
- Системы на основе LLM: 99.7% (структурированное извлечение с контекстуальным пониманием)
Понимание рукописного текста
В то время как классический OCR терпит неудачу с рукописными заметками, технология LLM интерпретирует даже неразборчивый почерк через контекст. Если что-то похожее на "15.3" появляется рядом с "Дата", система распознает дату.
Контекстуальное понимание
Сумма "1,247.83" распознается не только как число, но категоризируется как итоговая сумма счета. Система понимает отношения между различными элементами документа.
Многоязычные документы
Автоматическое определение языка и семантический перевод позволяют обрабатывать международные документы без отдельной настройки.
Сложные макеты
Вложенные таблицы, многоколоночные макеты и нерегулярные структуры правильно интерпретируются и выводятся в структурированном формате через ИИ-анализ.
Тест точности: Конкретные цифры
Точность распознавания на реальных бизнес-документах:
- Tesseract 4.0: 89-94% (чистые сканы), 65-80% (сложные документы)
- ABBYY FineReader: 96-98% (с обучением), 85-92% (из коробки)
- Системы на основе LLM: 99.7% (структурированное извлечение с контекстуальным пониманием)
Наиболее распространенные заблуждения при выборе технологии
Заблуждение 1: "OCR с открытым кодом дешевле"
Пример: Tesseract стоит $0, но при 1000 документов/месяц возникают $50,100/год трудозатрат на ручную постобработку. ABBYY стоит $35,000-80,000/год - затраты на ПО - лишь верхушка айсберга.
Заблуждение 2: "Наши документы слишком специфичны"
Системы на основе LLM изучают новые типы документов. То, что раньше требовало индивидуального программирования, теперь работает через обучение всего на нескольких образцах документов.
Заблуждение 3: "100% точность невозможна"
При правильной реализации LLM и контекстуальном понимании 100% точность извлечения данных действительно достижима - особенно со структурированными бизнес-документами.
Заблуждение 4: "Это слишком сложно для нас"
Современные ИИ-решения часто проще в использовании, чем вчерашнее OCR-программное обеспечение. Сложность переместилась от использования к разработке.
Техническая реальность: Как работают системы
Классический OCR (подход Tesseract)
Ввод: Отсканированный документ
↓
Предобработка изображения (удаление шума)
↓
Распознавание пиксельных паттернов (сопоставление шаблонов)
↓
Классификация символов
↓
Вывод: Неструктурированный текст
Обработка на основе LLM (подход PaperOffice)
Ввод: Документ (любой формат)
↓
Мультимодальный анализ (текст + макет + структура)
↓
Классификация типа документа на основе LLM
↓
Семантическое распознавание сущностей
↓
Контекстно-зависимое извлечение данных
↓
Контроль качества и генерация ограничивающих рамок
↓
Вывод: Структурированные данные со 100% точностью
Руководство по принятию решений: Что вам действительно нужно?
Интеллектуальный OCR -> PaperOffice OCR Max, достаточно если:
- В основном печатные, чистые документы
- Простые макеты без сложных структур
- Достаточно распознавания текста, извлечение данных не требуется
PaperOffice IDP Professional, необходимо если:
- Рукописный текст, штампы, сложные таблицы
- Различные типы документов и языки
- Требуется структурированное извлечение данных
- Планируется интеграция в ERP/CRM системы
- Критична безошибочная обработка
Гибридный подход (PaperOffice OCR+LLM+IDP) оптимален если:
- Смешанные типы документов
- Различные требования к качеству
- Планируется постепенная цифровизация
- Гибкость в бюджете и масштабировании
Практический тест: Попробуйте сами
Вместо теоретических дискуссий: Протестируйте 100-200 ваших типичных документов с различными системами. Возьмите реальные документы - смесь хороших и плохих сканов, различных макетов и языков.
Измеряйте:
- Точность извлечения
- Время на постобработку
- Возможность интеграции с вашими системами
- Масштабируемость при увеличении объема
Цифры говорят ясно: Компании, использующие обработку документов на основе LLM, сокращают ручную работу на 85-95% при достижении более высокой точности.
Заключение: Принимайте разумные решения вместо следования трендам
Технологический ландшафт кардинально изменился. В то время как классический OCR типа Tesseract все еще достаточен для очень простых случаев использования, системы на основе LLM, такие как PaperOffice, предлагают истинный интеллект документов.