










Максимально возможные предложения со скидками.
Исключительные новости из первых рук
Бесплатные бонусные обновления
Максимально возможные предложения со скидками.
Исключительные новости из первых рук
Бесплатные бонусные обновления
Дружба-Доверие-Пароль
Мы никогда не передадим ваш адрес электронной почты другим лицам, и каждое письмо будет содержать ссылку для однократного отказа от подписки.
FileOCRMax Technologie
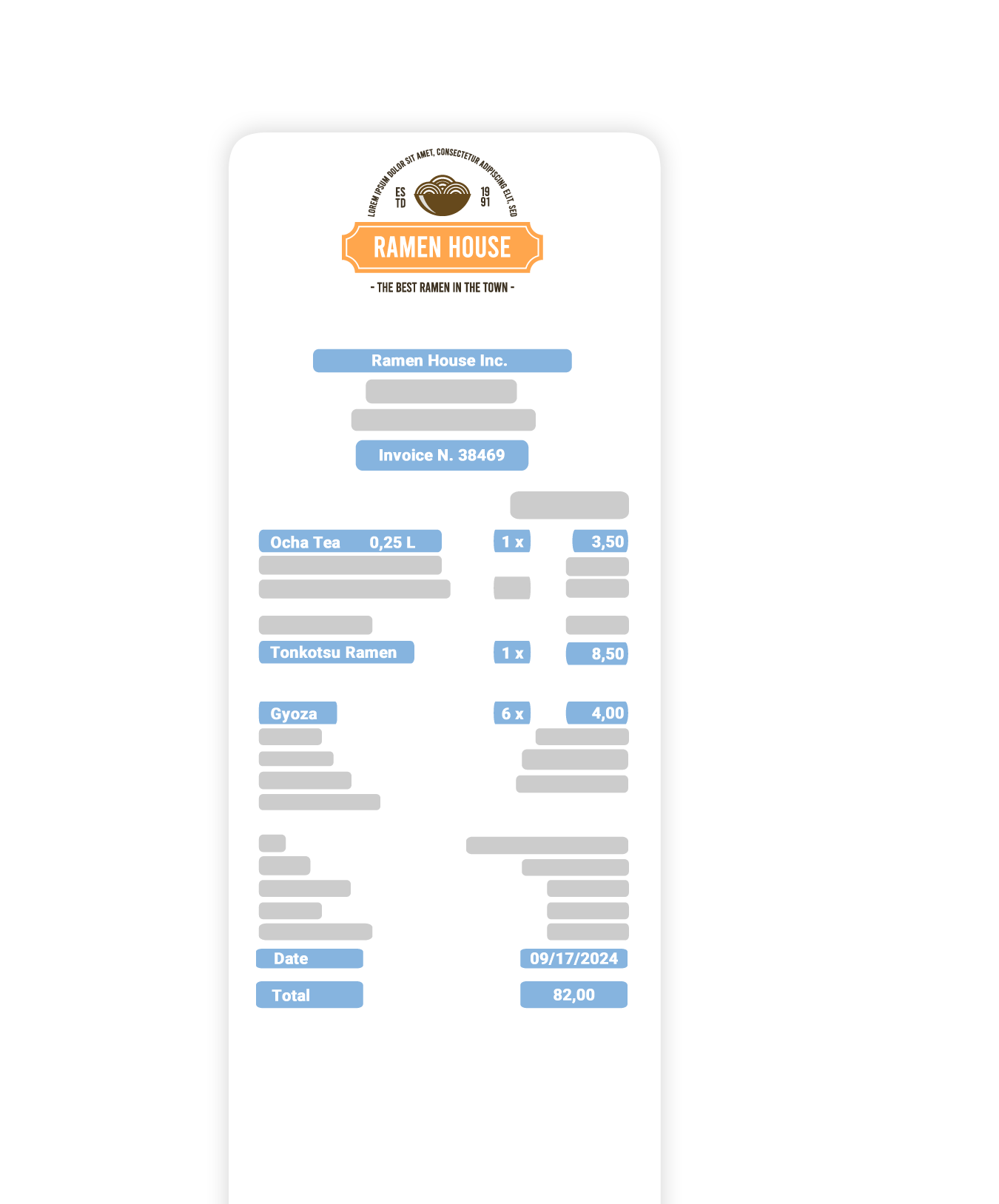
Революционное распознавание текста с использованием Large Language Models:
Извлекайте точную информацию из документов с максимальной точностью.
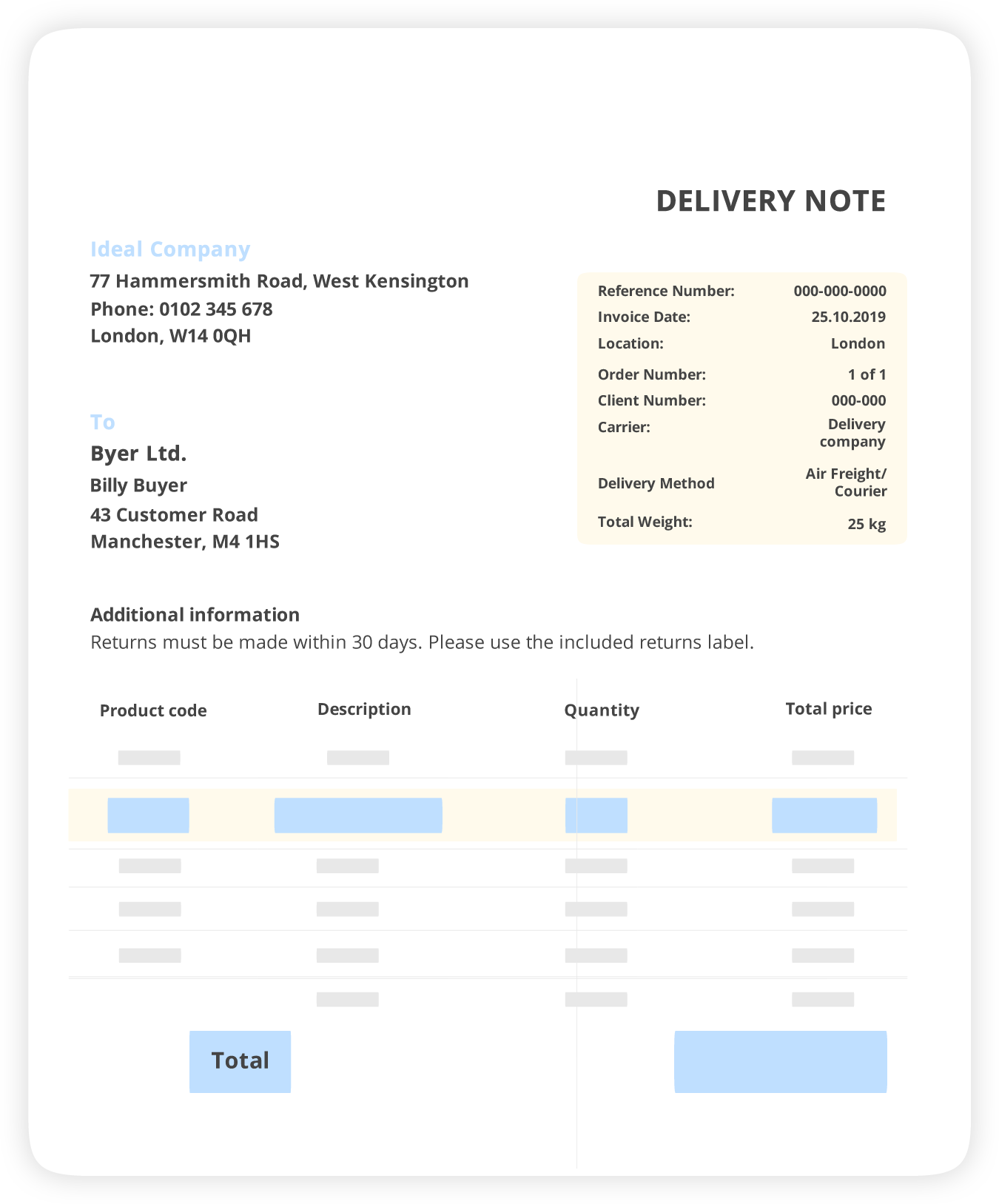
Считывайте автоматически каждый документ и получайте структурированные данные с точностью 100%.
Без установки / НЕ требуется кредитная карта / Никакой регистрации

Оптимизируйте обработку документов с помощью OCR на базе LLM
Extraktionsgenauigkeit durch LLM
Unterstützte Sprachen
Unbegrenzte Dokumententypen durch LLM-Analyse
Sofortige Flexibilität ohne Einschränkungen: Anders als herkömmliche Lösungen benötigt diese Technologie keine komplexe Konfiguration oder Vorlagen. Vom ersten Dokument an verarbeitet unsere OCR Texterkennung beliebige Dokumente mit höchster Genauigkeit.
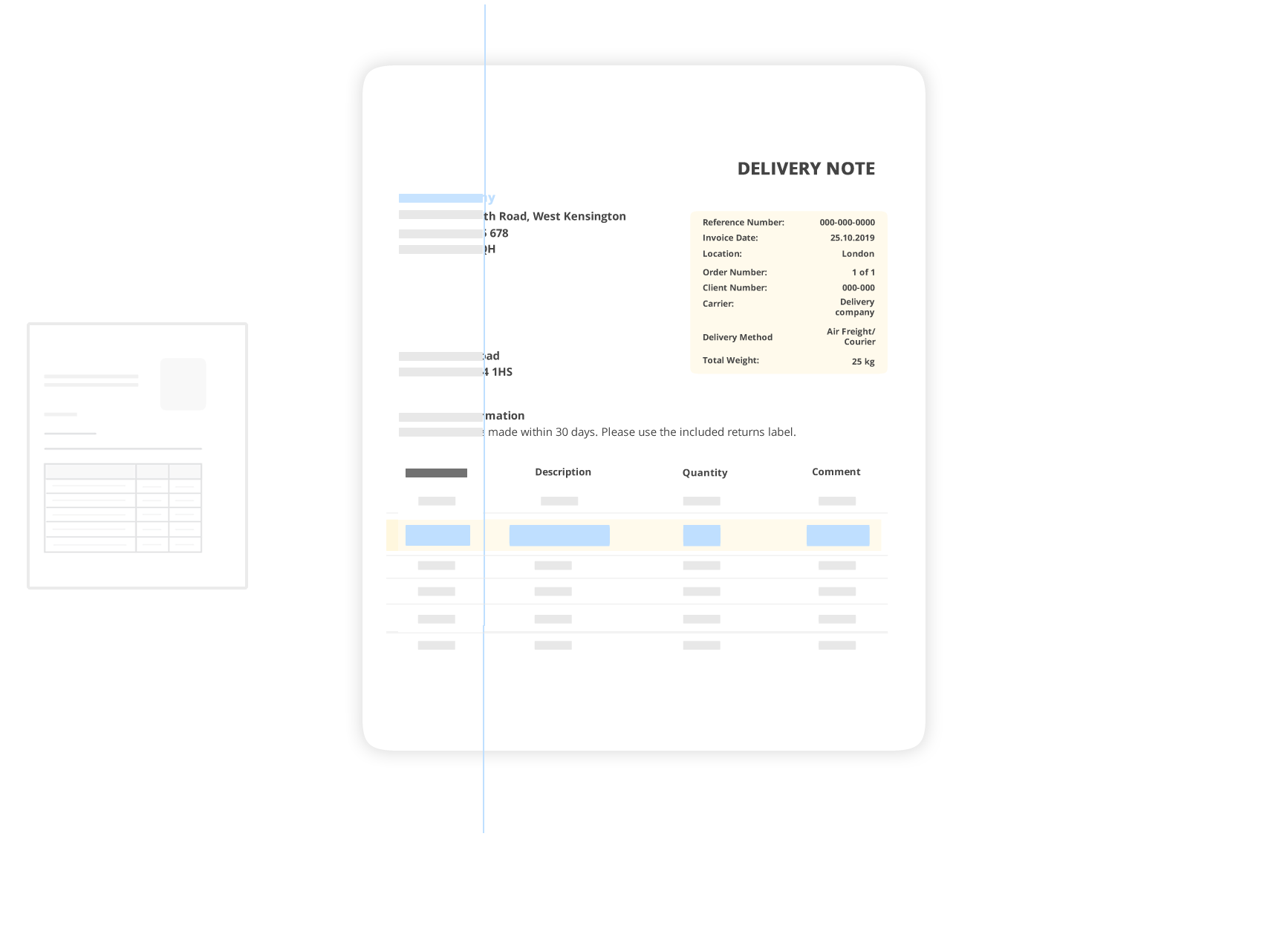
Was zuvor als White-Label-Technologie verfügbar war, bieten wir nun als eigenständige Lösung an. Profitieren Sie von der bewährten FileOCRMax-Technologie - jetzt mit noch mehr Funktionen und Anpassungsmöglichkeiten.
Schnelle Implementierung ohne komplexe Integration oder lange Einrichtungszeit.
Nahtlose Anbindung an bestehende Systeme über umfassende API-Schnittstellen.
End-to-End-Verschlüsselung und DSGVO-konforme Datenverarbeitung für sensible Dokumente.
Herkömmliche Machine Learning-basierte Systeme haben viele Nachteile, die Sie mit unserer OCR Texterkennung vermeiden können:

Unsere OCR-Lösung mit LLM-Integration bietet Funktionen, die weit über herkömmliche Texterkennungssysteme hinausgehen
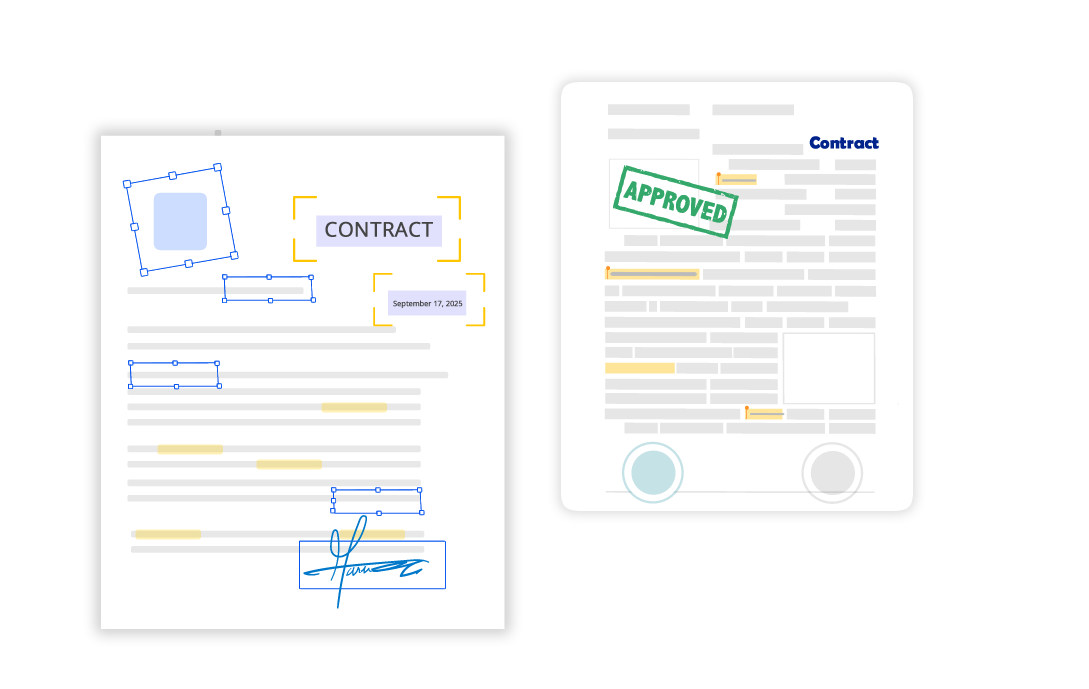
Unsere OCR Texterkennung deckt eine breite Palette von Dokumenttypen und Branchen ab, von Rechnungen bis zu komplexen Verträgen.

PaperOffice AI Suite помогла снизить уровень ошибок при сборе данных на 99% и одновременно увеличить скорость обработки в 50 раз.
Моника Риттер
Генеральный директор

Благодаря PaperOffice AI Suite весь документооборот был оптимизирован, что привело к ежегодному сокращению 86% ручной нагрузки.
Ларс-Р. Лудевиг
Генеральный директор

Благодаря внедрению PaperOffice AI Suite, управление недвижимостью для 2,500 единиц было оптимизировано с помощью автоматизированного сбора данных, более 95% ручных вмешательств было устранено, а производительность компании удвоена.
ИТ-отдел

Патриархат Лиссабона использует PaperOffice AI Suite для ускорения классификации документов в бухгалтерии и управлении на 90%. В результате рабочие процессы стали 70% более эффективными, что позволило сэкономить ценные ресурсы.

PaperOffice AI Suite позволила обрабатывать более 10,000 документов в день без ошибок и за рекордное время, что значительно улучшило рабочий процесс.
Абрахам Ялип
IT-специалист

Революционизирует обработку документов с помощью PaperOffice AI Suite, мощного решения, которое выводит эффективность и точность обработки сложных документов на новый уровень благодаря интеллектуальной обработке документов (IDP), автоматизированным рабочим процессам и искусственному интеллекту (ИИ)
Штефан Райхель
Генеральный директор

IDC Construcción S.L. трансформирует управление строительными проектами с помощью PaperOffice AI Suite. Благодаря интеллектуальной обработке документов, рабочие процессы автоматизируются, документы обрабатываются точно, а эффективность на каждом этапе строительного проекта увеличивается на 50%.
Агустин Гарсия Афонсо
IT-специалист

Инновационные решения для технической обработки документов: Herrmann GmbH Инженерное бюро оптимизирует рабочие процессы с помощью PaperOffice AI Suite. Благодаря точной экстракции данных и бесшовной интеграции, эффективность была увеличена на 60%, в то время как время обработки документов было сокращено на 50%.

PaperOffice AI Suite улучшила услуги здравоохранения благодаря эффективному управлению данными и точной обработке, увеличив продуктивность на 40% и сократив время обработки заказов на 30%, что привело к значительно более плавному процессу выполнения заказов.
Энрике Сантос
Генеральный директор

Инновационная автоматизация для сектора здравоохранения: Hartung Care Service революционизирует амбулаторное обслуживание с помощью PaperOffice AI Suite. Благодаря точной обработке данных и бесшовной интеграции время реакции на запросы пациентов было увеличено на 50%, а количество ошибок в документации было снижено – для современного и ориентированного на пациента обслуживания.

PaperOffice AI Suite помогла снизить уровень ошибок при сборе данных на 99% и одновременно увеличить скорость обработки в 50 раз.

Благодаря PaperOffice AI Suite весь документооборот был оптимизирован, что привело к ежегодному сокращению 86% ручной нагрузки.

Внедрение PaperOffice AI Suite привело к 60-кратному ускорению классификации документов и одновременно оптимизировало извлечение данных.

PaperOffice AI Suite революционизировала процессы правоохранительных органов благодаря точной экстракции данных из рукописных бланков приема, минимизируя ручные ошибки на 90% и значительно улучшив принятие решений и время реакции на 40%.
Лейтенант МакМуллен
Лейтенант
Entdecken Sie unsere vorgefertigten KI-Modelle und nutzen Sie sofort einsatzbereite Dokumenten-Workflows für maximale Effizienz.
+44 20 39361675