最高可优惠折扣
独家内幕新闻
免费额外升级
最高可优惠折扣
独家内幕新闻
免费额外升级
友谊 信任 信言不凿
我们绝对不会将您的电子邮件地址提供给其他人,每封电子邮件中都包含一个一键退订链接。
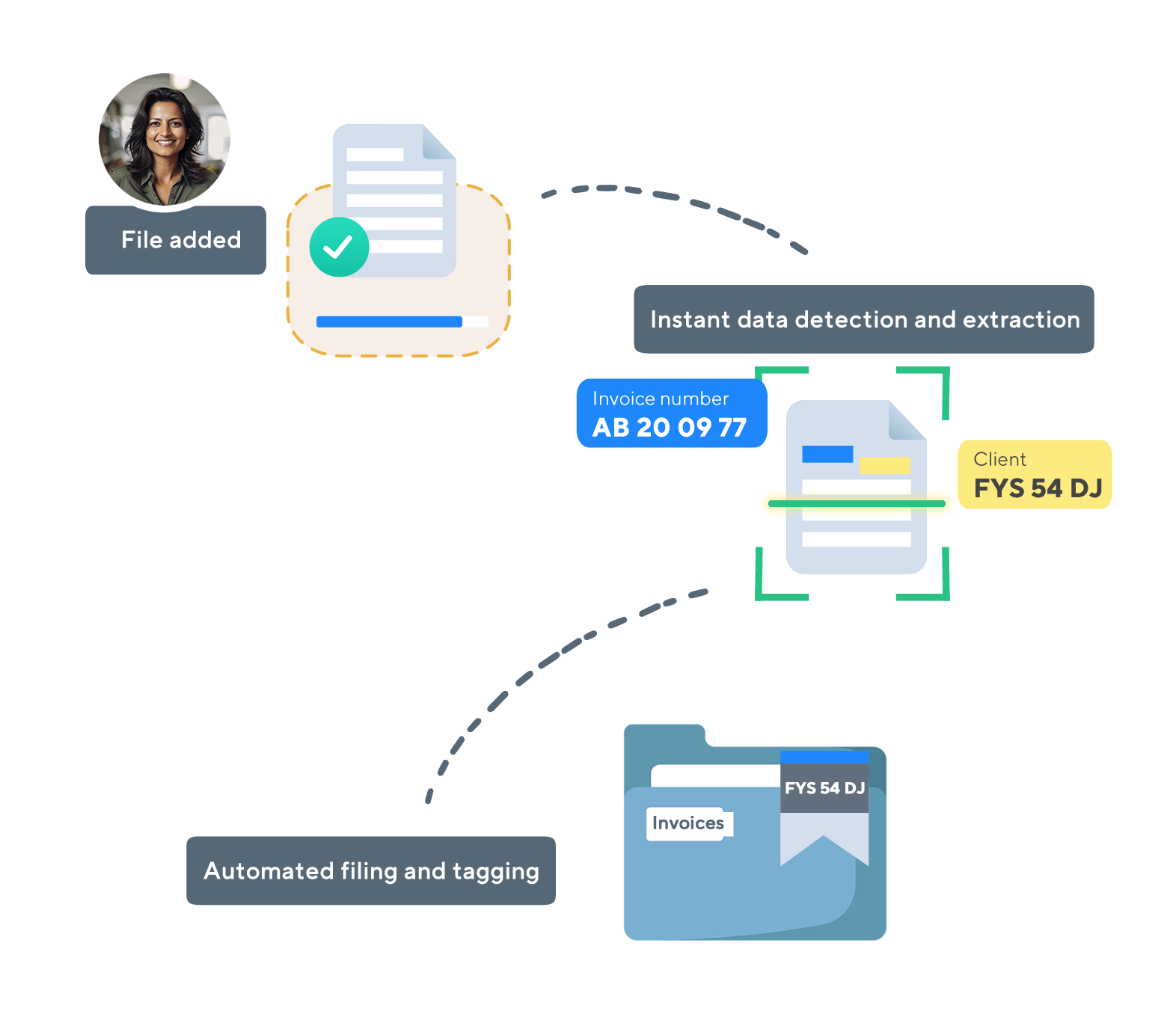
PaperOffice提供了一种高效的解决方案,用于自动化抓取和处理进项发票以及符合审计标准的存档。
通过监视文件夹,新发票会被自动抓取和处理,这样既节省了时间,又减少了错误。优化您的会计流程,提高企业的效率。
但我们提供的不仅仅是这些 - 我们还提供基于数据的洞察和行业领先的效率,以满足您的需求。
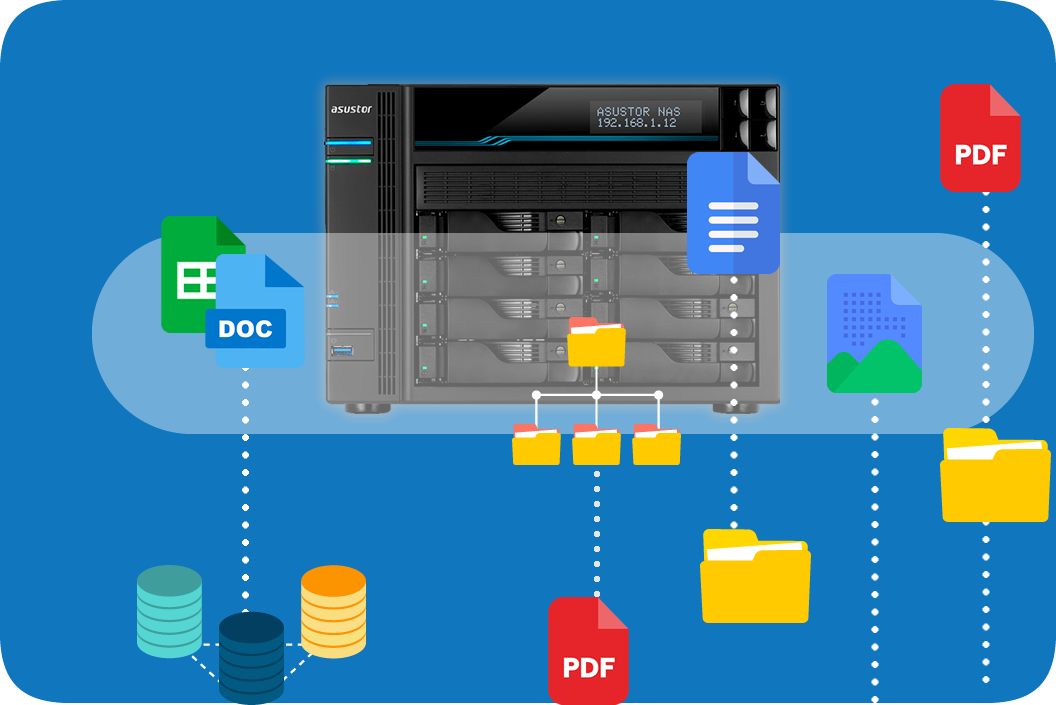
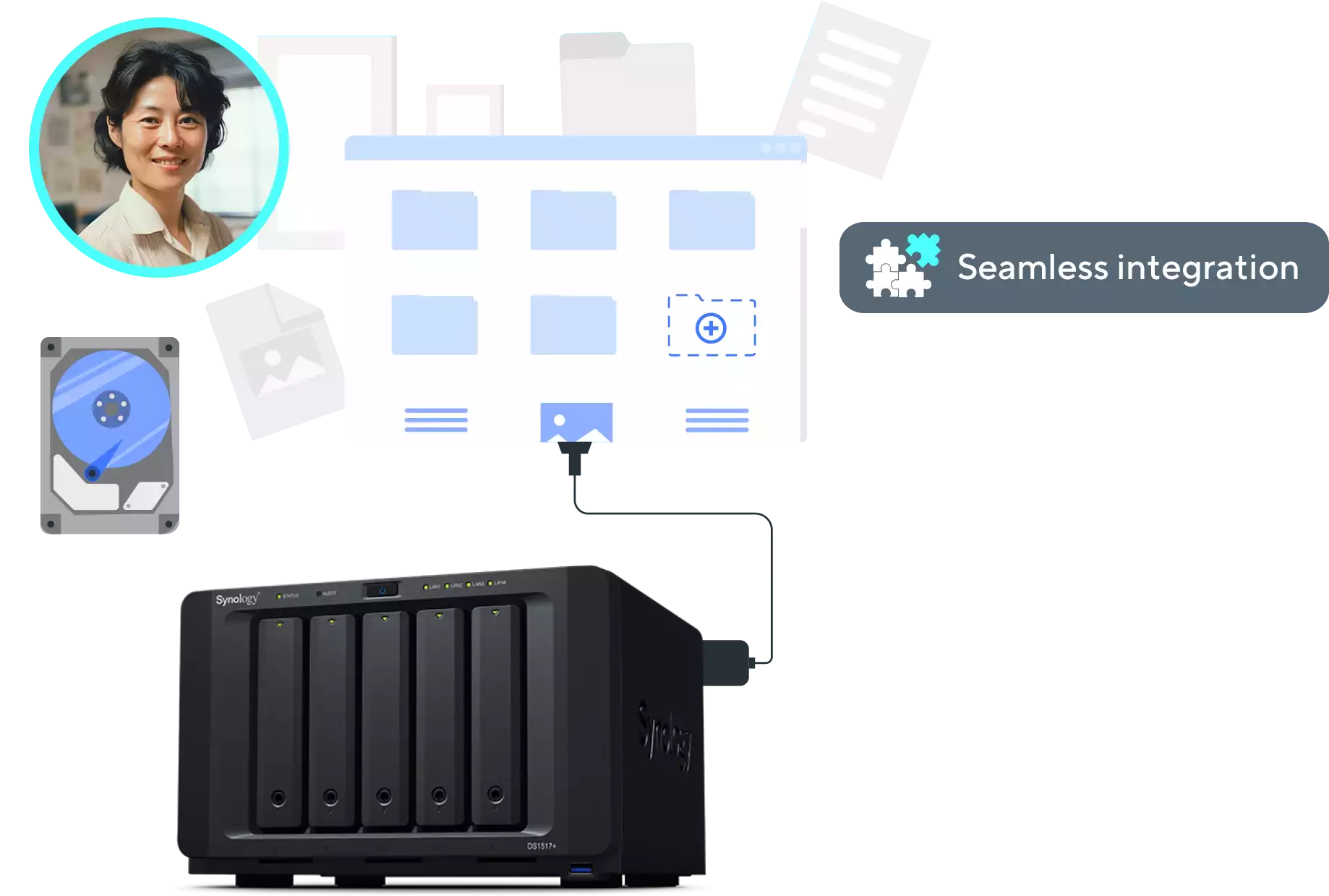
PaperOffice 使用来自 Synology NAS 的强大数据库,为管理和保护您的文件提供了一个强大的平台。
这种集成使您能够结合使用 PaperOffice 的先进功能和您现有的 Synology 基础设施,使您的文档管理更高效、更安全。

ERROR: LID-43373 missing API ERROR: LID-43374 missing:
ERROR: LID-43384 missing ERROR: LID-43385 missing.
![]()
出于充分的理由,领先的NAS制造商QNAP只信赖PaperOffice。
因为PaperOffice是全球所有QNAP NAS设备的唯一官方DMS。
而且这是60,000台设备。每个月。
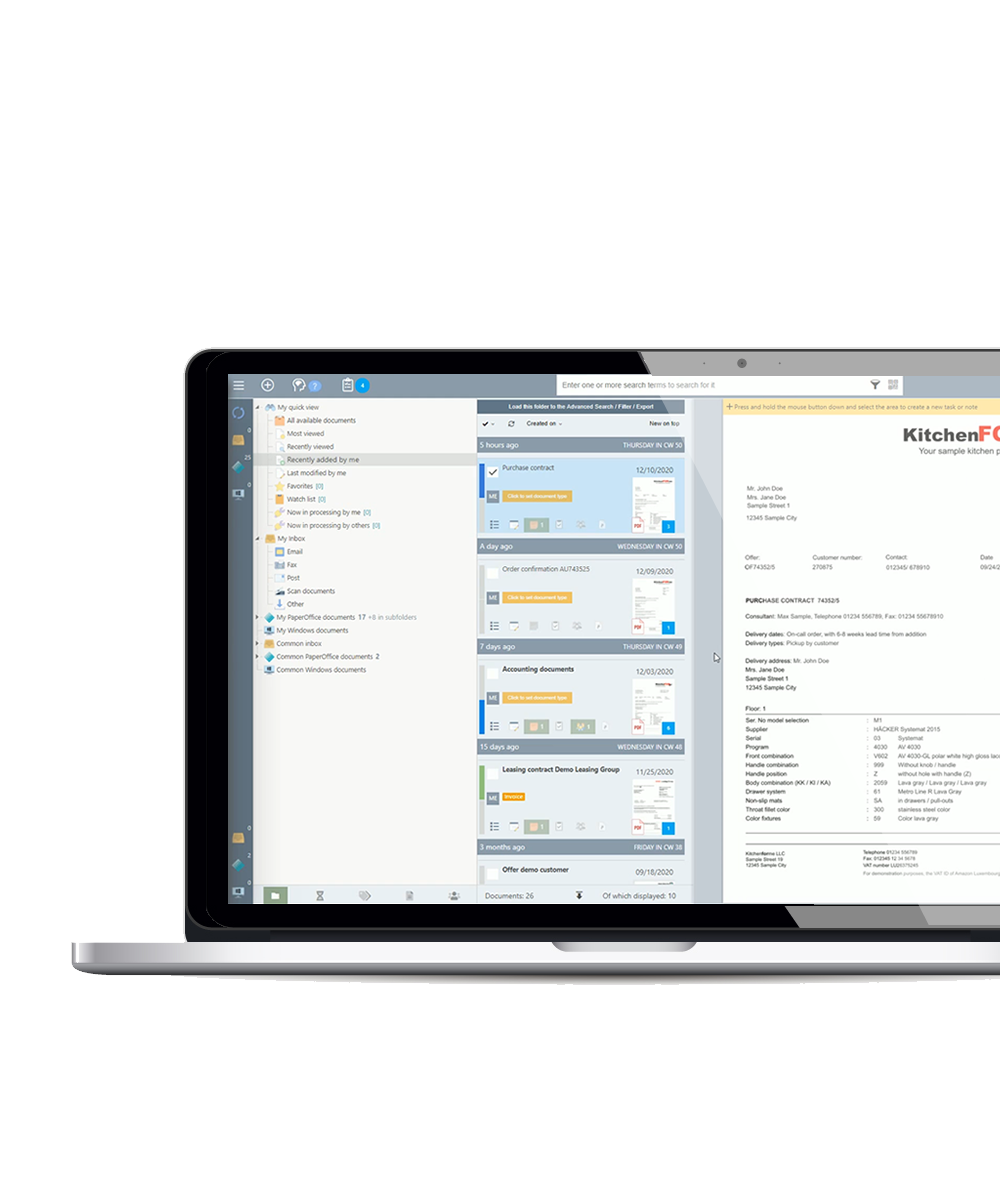
优化您的文档管理:快速而精确的OCR文本识别用于扫描文档的批量扫描和大量处理与PaperOffice。PaperOffice轻松接管您已有的文档。
扫描仪和文档管理软件如PaperOffice在此中扮演关键角色,帮助企业实现文档数字化、组织和管理。

PaperOffice 通过一个集中平台实现不同参与者的无缝协作 - 从内部团队到外部合作伙伴。
我们的解决方案为您提供控制,能够有针对性地管理个性化访问权限,并确保每位行动者精确获取他所需的信息。体验在协作中的最大安全性和效率。
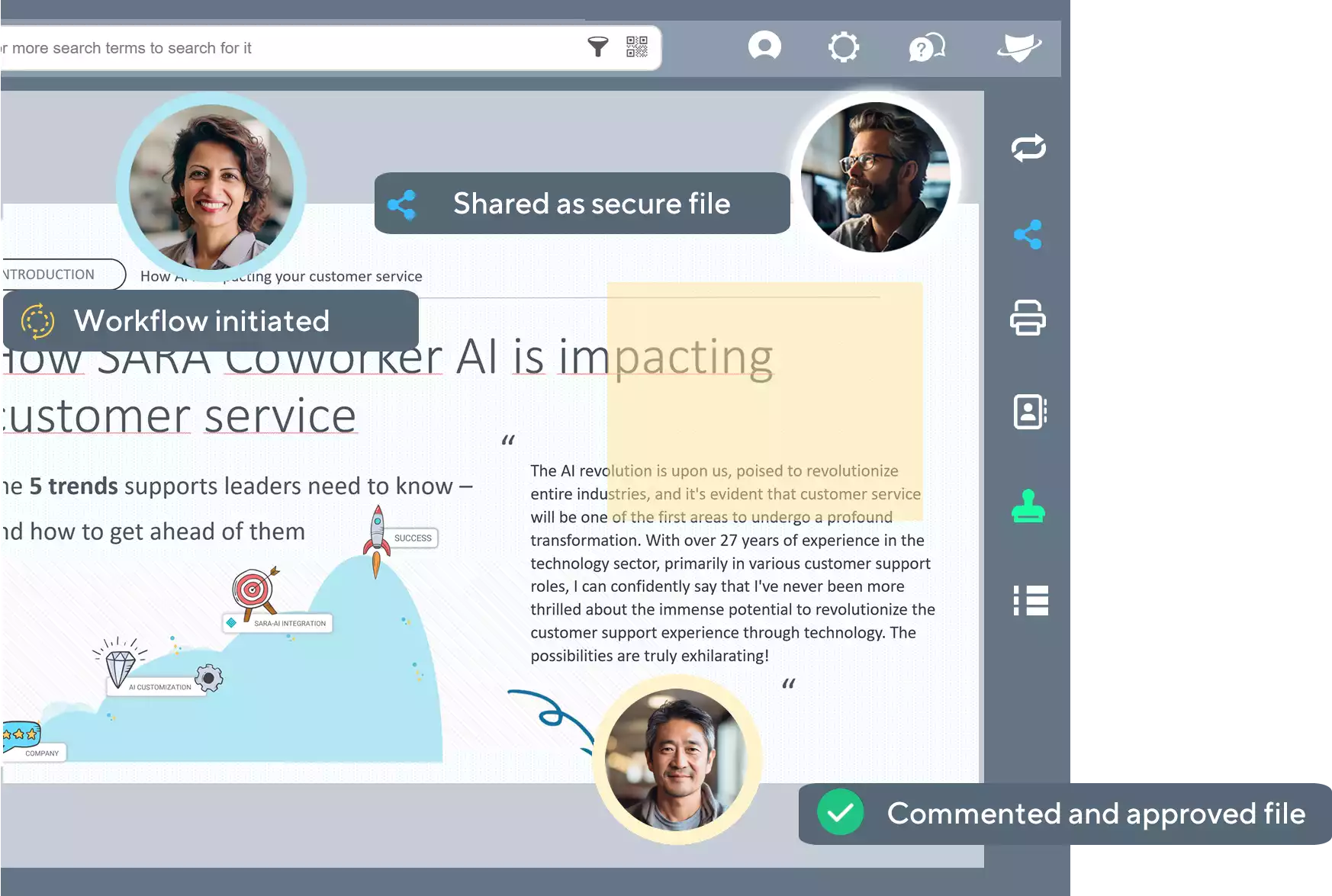
发现 PaperOffice 的文档管理独特世界,这是专为 QNAP NAS 设备提供的独家DMS系统。作为全球唯一授权的解决方案,PaperOffice 提供无缝集成,优化您的工作流程并可靠地保护您的数据。从这个独特的合作伙伴关系中受益,提高您的文档管理效率。